Legacy Schema in Maintenance Mode
The legacy schema will no longer be available to query for customers on Oct 15, 2024
Child tables for complex elements in FHIR resources
For elements in a resource that are complex, rectangularization offers child tables that express the values in that complex element of the parent as scalars for analytic convenience. For example, the Patient resource has an address element of data type Address that includes the street, city, state, and postal code.
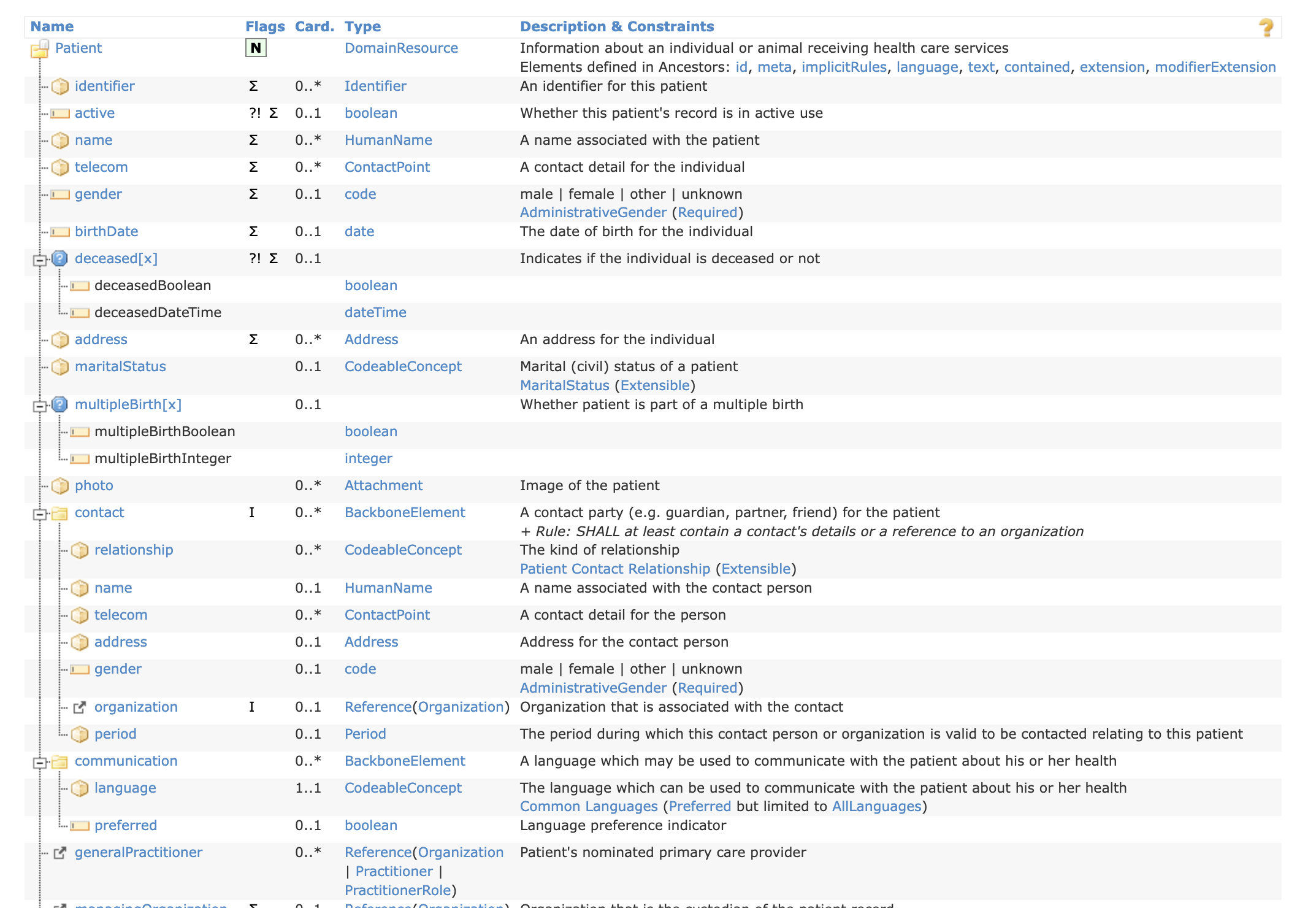
The structure of a Patient FHIR resource

The structure of an Address FHIR data type
The data mart includes a Patient table and PatientAddress child table that can be joined to the Patient table by the patient_id column.
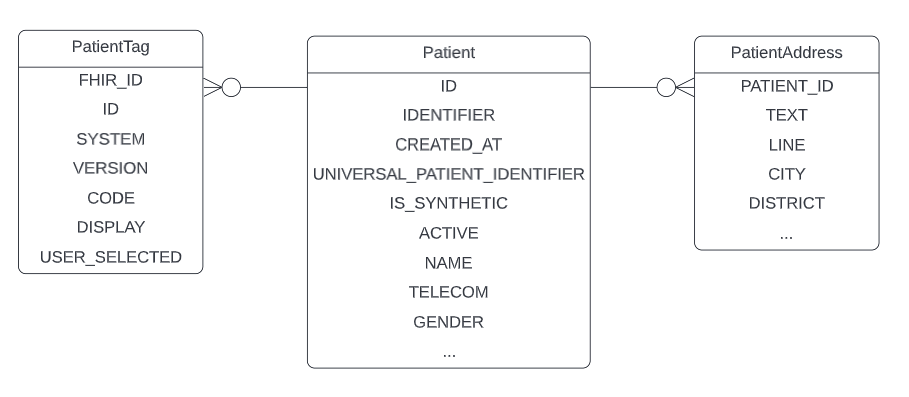
All child tables have columns that contain the ID field of the parent resource.
| Parent Resource | Child Tables | Join Keys |
|---|---|---|
| MedicationDispense | MedicationDispenseAuthorizingPrescription | - MedicationDispense on medication_dispense_id - MedicationRequest on medication_request_id |
| MedicationDispense | MedicationDispenseDosageInstruction | MedicationDispense on id |
| MedicationRequest | MedicationRequestDosageInstruction | MedicationRequest on id |
| Observation | ObservationPerformer | - Observation on id - Practitioner on reference_id |
| Organization | OrganizationAddress OrganizationContact OrganizationIdentifier OrganizationTelecom | Organization on id |
| Patient | PatientAddress PatientCommunication PatientContact PatientGeneralPractitioner | Patient on patient_id |
| Practitioner | PractitionerAddress PractitionerQualification PractitionerTelecom | Practitioner on id |
Extracting JSON data in arrays and structures of complex elements
FHIR resources are complex and can include elements with cardinalities greater than one and with embedded data types. For example, a Patient resource can have any number of identifiers through the Identifier data type.
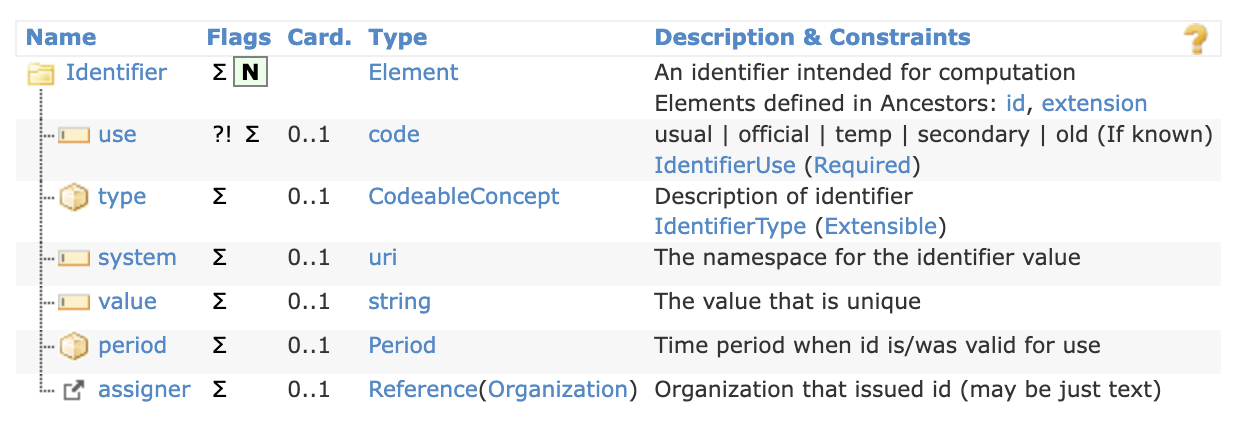
The Identifier FHIR data type includes use, type, system, value, period, and assigner elements.
Suppose you want to extract all patients with your system’s identifier. Querying for the identifier column in the Patient table would return an array of Identifier structs.
select identifier from patient
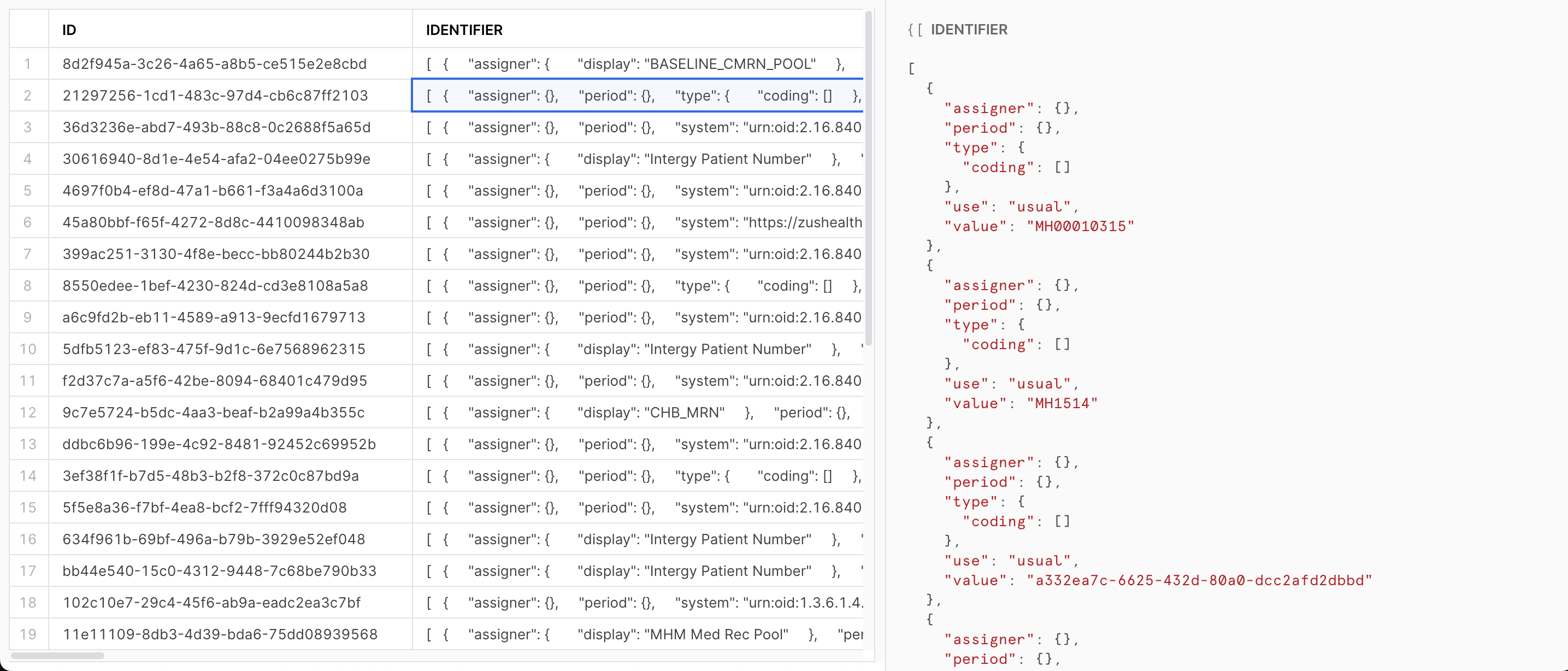
[
{
"assigner": {},
"period": {},
"type": {
"coding": []
},
"use": "usual",
"value": "MH00010315"
},
{
"assigner": {},
"period": {},
"type": {
"coding": []
},
"use": "usual",
"value": "MH1514"
},
{
"assigner": {},
"period": {},
"type": {
"coding": []
},
"use": "usual",
"value": "a332ea7c-6625-432d-80a0-dcc2afd2dbbd"
},
{
"assigner": {},
"period": {},
"system": "https://zusapi.com/fhir/identifier/universal-id",
"type": {
"coding": []
},
"value": "4901b5b1-6abc-469c-b88a-abfda5b58460"
}
]
Therefore, you would need to explode the array of identifiers in the Identifier column in the Patient table into multiple rows and produce an inline view that references Patient columns. In Snowflake, this can be achieved with the lateral keyword and the flatten table function.
The flatten table function outputs a fixed set of columns:
| SEQ | KEY | PATH | INDEX | VALUE | THIS |
| Column Name | Column Description |
|---|---|
| SEQ | A unique sequence number associated with the input record. The sequence is not guaranteed to be gap-free or ordered in any particular way. |
| KEY | For maps or objects, this column contains the key to the exploded value. |
| PATH | The path to the element within a data structure which needs to be flattened. |
| INDEX | The index of the element, if it is an array; otherwise NULL. |
| VALUE | The value of the element of the flattened array/object. |
| THIS | The element being flattened (useful in recursive flattening). |
Flattening the Identifier column outputs a single JSON identifier from the Identifier column array in the VALUE column. To traverse a path in a JSON object in Snowflake, the dot notation is used.
<column>:<level1_element>.<level2_element>.<level3_element>
For more information on querying semi-structured data in Snowflake, including the dot notation and bracket notation, please refer to Snowflake's user guide.
The lateral keyword and flatten function can be combined as follows:
select
patient.id,
identifiers.VALUE:use as identifier_use,
identifiers.VALUE:type as identifier_type,
identifiers.VALUE:system as identifier_system,
identifiers.VALUE:value as identifier_value,
identifiers.VALUE:period as identifier_period,
identifiers.VALUE:assigner as identifier_assigner
from patient,
lateral flatten(input => identifier) as identifiers
where identifier_system = 'https://zusapi.com/fhir/identifier/universal-id'
Analyzing prevalence of patients’ zipcodes
The query below counts the number of distinct patients by zip code in descending order. A patient may be counted in more than one zip code.
select
left(pa.postal_code, 5) as zip_code,
count(distinct p.universal_patient_identifier) as distinct_upid_count
from patient p
left join patientaddress pa
on p.id = pa.patient_id
group by zip_code
order by distinct_upid_count desc
Analyzing prevalence of Conditions
Zus helps Builders clean up real-world data with enrichment and aggregation engines to make data more usable and easier to query. Conditions and medication-related FHIR resources written to the Zus platform, including data from third party partner networks, are enriched.
First, confirm the 95%+ coverage of SNOMED codes, including Zus-enriched SNOMED codes, with the query below.
select
contains(code:coding, 'http://snomed.info/sct') as snomed_coded,
count(distinct id)
from condition
group by 1
The query below counts the number of distinct patients by SNOMED code in Condition resources in descending order.
with condition_snomed_codes as (
select
condition.*,
codes.VALUE:code as code_code,
codes.VALUE:display as code_display,
codes.VALUE:system as code_system
from condition,
lateral flatten(input=>code:coding) as codes
where code_system = 'http://snomed.info/sct')
select
code_code,
code_display,
count(distinct universal_patient_identifier) as distinct_upid_count
from condition_snomed_codes
group by code_code, code_display
order by distinct_upid_count desc
Analyzing prevalence of Medications summarized by Zus
For third-party FHIR resources, their data source is available in the DATA_SOURCE column, which is otherwise NULL. To identify Zus-summarized and de-duplicated Lens data, you can leverage the TAG suffix table. The query below counts the number of distinct patients by RxNorm code in summary MedicationStatement Lens resources in descending order.
with summary_medication_rxnorm_codes as (
select
medicationstatement.*,
codes.VALUE:code as code_code,
codes.VALUE:display as code_display,
codes.VALUE:system as code_system
from medicationstatement
join medicationstatementtag
on medicationstatement.id = medicationstatementtag.fhir_id
and medicationstatementtag.system = 'https://zusapi.com/summary',
lateral flatten(input=>medication_codeable_concept:coding) as codes
where code_system = 'http://www.nlm.nih.gov/research/umls/rxnorm')
select
code_code,
code_display,
count(distinct universal_patient_identifier) as distinct_upid_count
from summary_medication_rxnorm_codes
group by code_code, code_display
order by distinct_upid_count desc
Identifying patients with at least one A1C Observation
The A1C test measures average blood sugar levels over the past 3 months and is commonly used to diagnose prediabetes and diabetes. To identify patients with at least one A1C test, first characterize the types of systems and codes that are used to signify the A1C test from most to least common.
select distinct
codes.VALUE:code as code_code,
codes.VALUE:system as code_system,
codes.VALUE:display,
count(distinct id)
from observation,
lateral flatten(input=>code:coding) as codes
where lower(codes.VALUE:display) like '%a1c%'
group by 1,2,3
order by 4 desc ;
Mapping from the Zus Universal Patient Identifier to your internal identifier
The query returns a 1:1 mapping between the Zus Universal Patient Identifier and an internal identifier labeled with system, 'https://organizationName.com/ID'.
select
patient.universal_patient_identifier as zus_upid,
identifiers.VALUE:value::string as organization_patient_id
from patient,
lateral flatten (input => identifier) as identifiers
where identifiers.VALUE:system = 'https://organizationName.com/ID' ;
Updated 8 months ago